- 烈焰私服





谷歌全新轻量级新模型ALBERT刷新三大NLP基准!
-
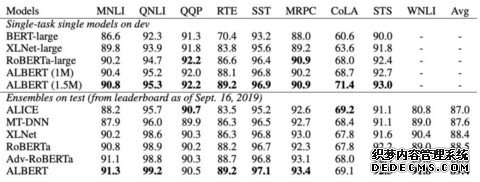
我们在 GLUE、SQuAD 和 RACE 三大自然语言理解基准测试上都得到了新的SOTA结果:在 RACE 上的准确率提高到 89.4%,在 GLUE 上的得分提高到 89.4,在 SQuAD 2.0 上的 F1 得分达到 92.2。
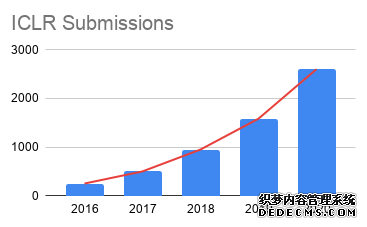
【新智元导读】ICLR 2020提交论文数量达到2594篇,比去年增加了近1000篇。其中,来自谷歌的一篇论文引起格外瞩目,该论文提出ALBERT模型,比BERT-large 参数更少,却在GLUE、RACE和SQuAD三大NLP基准测试中取得第一。>>>人工智能改变中国,我们还要跨越这三座大山 | 献礼70周年
基于此方法的最佳模型在GLUE、RACE和SQuAD基准上都得到了最新的SOTA结果,而且与BERT-large相比,参数更少。
https://openreview.net/group?id=ICLR.cc/2020/Conference
构建更大的模型的一个障碍是可用硬件的内存限制。考虑到目前最先进的模型通常有数亿甚至数十亿个参数,当我们试图扩展模型时,很容易遇到这类限制。在分布式训练中,训练速度也会受到很大的影响,因为通信开销与模型参数的数量成正比。
为了进一步提高ALBERT的性能,我们还引入了一个用于句子顺序预测(sentence-order prediction ,SOP)的自监督损失。SOP 主要聚焦于句子间的连贯,旨在解决原始BERT模型中下一句预测(NSP)损失低效的问题。
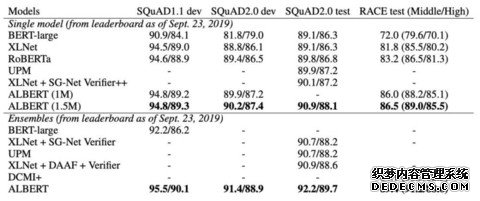
表10:GLUE基准测试的State-of-the-art 结果。
原标题:谷歌全新轻量级新模型ALBERT刷新三大NLP基准! 来源:腾讯网
ICLR 2019 共收到 1591 篇论文投稿,其中 oral 论文 24 篇,poster 论文 476 篇。
不久,终于有网友扒出了这个模型的论文,原来是 ICLR 2020 的一篇投稿,出自谷歌。
论文地址:
第二种技术是跨层参数共享(cross-layer parameter sharing)。这种技术可以防止参数随着网络深度的增加而增加。
谷歌研究人员对此提出了通过两种参数约简技术来降低内存消耗,加快 BERT 的训练速度的思路,于是就有了 ALBERT。
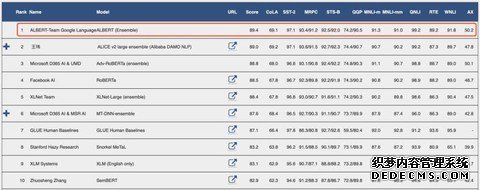
ALBERT在GLUE benchmark上排名第一

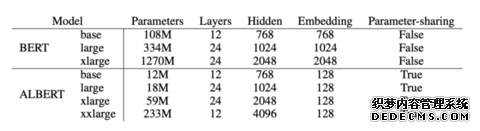
BERT和ALBERT模型的规模
ICLR 2020 更疯狂,,到9月25日论文提交截止日期,已投稿的论文有2594篇!
针对上述问题,现有解决方案包括模型并行化(Shoeybi et al.,2019)和智能内存管理(Chen et al., 2016); Gomez et al., 2017)。这些解决方案解决了内存限制问题,但没有解决通信开销和model degradation问题。在本文中,我们通过设计一个比传统BERT架构参数少得多的架构来解决上述所有问题,称为A Lite BERT (ALBERT)。
在训练自然语言表示时,增加模型大小通常会提高下游任务的性能。然而,在某种程度上,由于GPU/TPU内存的限制、更长的训练时间以及意想不到的model degradation,进一步增大模型会变得更加困难。
事情经过是这样的:
ALBERT 又叫 A LITE BERT,顾名思义就是一个轻量级的 BERT 模型。模型大固然效果好,但也超吃资源。训练一次不仅耗时、更费钱。甚至在某些情况下,由于 GPU/TPU 内存限制、训练时间延长以及意外的模型退化等原因,更难提升模型大小。
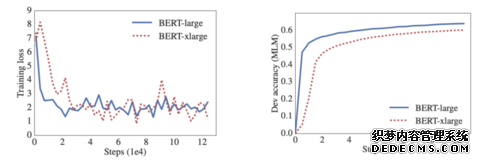
我们还观察到,简单滴增加模型的hidden size可能会导致性能下降,比如BERT-large。表1和图1给出了一个典型的例子,我们简单地将这个BERT-xlarge模型的hidden size增加到2倍,结果却很糟糕。
这两种方法都在不严重影响性能的前提下,显著减少了BERT的参数数量,从而提高了参数效率。ALBERT的配置类似BERT-large,但参数量少了18倍,并且训练速度快1.7倍。参数约简技术还可以作为一种形式的正则化,可以使训练更加稳定,并且有助于泛化。
当然这也不算特别震惊,毕竟最近几年顶会论文的疯狂增长大家早就有了心理准备。
https://openreview.net/pdf?id=H1eA7AEtvS
实验表明,本文提出的方法得到的模型比原始BERT模型更好。我们还使用 self-supervised loss,专注于建模句子间的连贯性,并表明它始终有助于多句子输入的下游任务。
接下来,我们就来看一下这篇 ICLR 2020 投稿论文,来一探这个神仙模型的究竟。
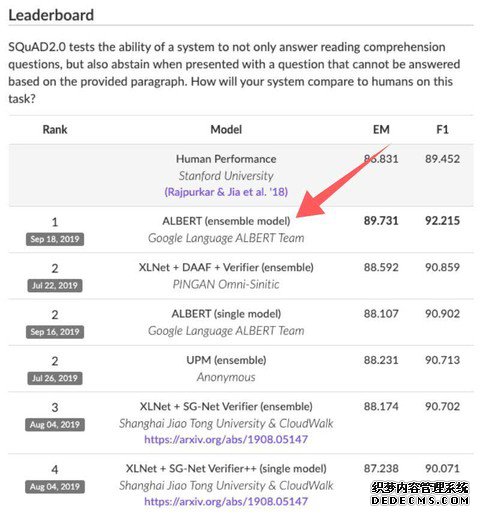
有Reddit网友发现,一个叫做 ALBERT 的模型,在 SQuAD 2.0 leaderboard 和 GLUE benchmark 都达到了最佳水准。这是一个前所未见的新模型,引起了大家的好奇。
为了解决这些问题,谷歌的研究人员提出了两种参数约简技术,以降低内存消耗,并提高BERT的训练速度。
由图灵奖获得者、人工智能巨头Yoshua Bengio 和 Yann LeCun牵头创办的顶级会议ICLR,被誉为深度学习“无冕之王”,获得学术研究者们广泛认可。
ALBERT结合了两种参数约简(parameter reduction)技术,消除了在扩展预训练模型时的主要障碍。
基于这些设计,ALBERT能够扩展到更大的版本,参数量仍然比BERT-large少,但是性能明显更好。
表11:在SQuAD 和 RACE 两个基准测试上的State-of-the-art 结果
图1:较大模型的masked LM精度较低,但没有明显的过拟合迹象。
新智元报道
表1:在RACE测试中,增加BERT-large的hidden size导致模型性能下降。
ALBERT在SQuAD 2.0上排名第一
编辑:小芹,鹏飞
第一个技术是对嵌入参数化进行因式分解(factorized embedding parameterization)。通过将大的词汇表嵌入矩阵分解为两个小的矩阵,将隐藏层的大小与词汇表嵌入的大小分离开来。这种分离使得在不显著增加词汇表嵌入的参数大小的情况下,更容易增加隐藏大小。
制霸三大基准测试,ALBERT用了两招
在这么多投稿中,一篇来自谷歌的论文很快引起研究社区瞩目。该论文提出一个名为ALBERT的模型,比BERT-large 参数更少,却在 GLUE 基准远远甩开 BERT-Large 拿到榜首。不仅如此,该模型横扫 GLUE、RACE 和 SQuAD,以显著的优势稳坐第一。

全部论文: