- 烈焰私服





谷歌ALBERT模型V2+中文版来了:刷新NLP各大基准
-
中文版下载地址
[Tar File]:
https://tfhub.dev/google/albert_base/2
https://tfhub.dev/google/albert_xxlarge/2
https://storage.googleapis.com/albert_models/albert_large_zh.tar.gz
https://storage.googleapis.com/albert_models/albert_xlarge_v2.tar.gz
https://storage.googleapis.com/albert_models/albert_base_zh.tar.gz
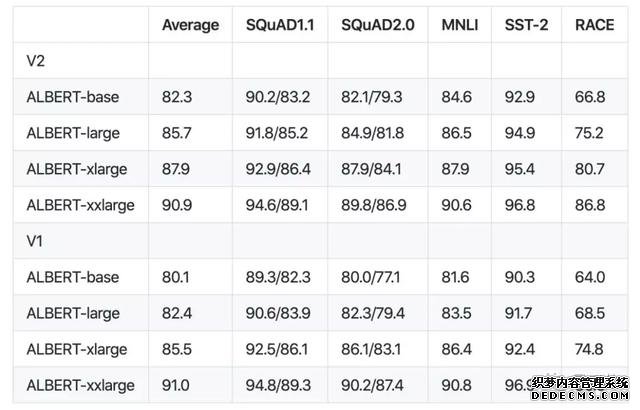
平均来看,ALBERT-xxlarge比v1略差一些,原因有以下2点:
https://storage.googleapis.com/albert_models/albert_large_v2.tar.gz
[Tar File]:
ALBERT v2下载地址
https://tfhub.dev/google/albert_xlarge/2
[Tar File]:
ALBERT 2性能再次提升
Xxlarge
比BERT模型参数小18倍,性能还超越了它。
Base
https://tfhub.dev/google/albert_large/2
https://storage.googleapis.com/albert_models/albert_xxlarge_zh.tar.gz
[TF-Hub]:
https://github.com/google-research/ALBERT
https://storage.googleapis.com/albert_models/albert_xxlarge_v2.tar.gz
说明采用上述三个策略的重要性。
这就是谷歌前不久发布的轻量级BERT模型――ALBERT。
从性能的比较来说,对于ALBERT-base、ALBERT-large和ALBERT-xlarge,v2版要比v1版好得多。
[TF-Hub]:
https://storage.googleapis.com/albert_models/albert_xlarge_zh.tar.gz
[TF-Hub]:
[Tar File]:
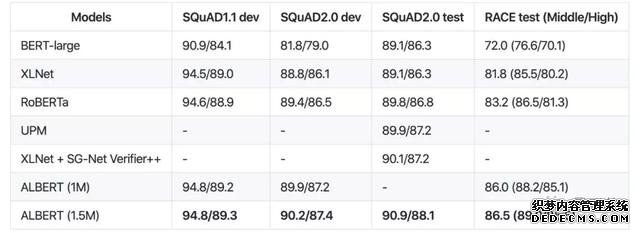
变态烈焰sf-xxl使用了一个单模型设置,在SQuaD和RACE基准测试中的性能:
额外训练了1.5M步(两个模型的唯一区别就是训练1.5M和3M步);
GitHub项目地址:
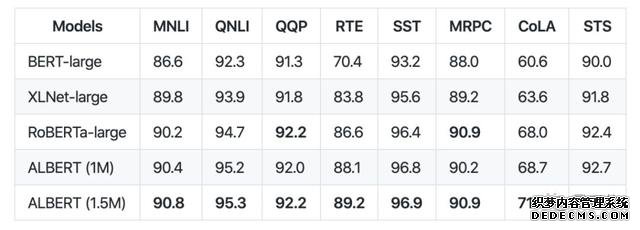
变态烈焰sf使用了一个单模型设置,在 GLUE 基准测试中的性能:
在这个版本中,“no dropout”、“additional training data”、“long training time”策略将应用到所有的模型。
中文版下载地址
XLarge
https://storage.googleapis.com/albert_models/albert_base_v2.tar.gz
XLarge
总的来说,变态烈焰sf是BERT的轻量版, 使用减少参数的技术,允许大规模的配置,克服以前的内存限制。
不仅如此,还横扫各大“性能榜”,在SQuAD和RACE测试上创造了新的SOTA。

Large

对于v1,在BERT、Roberta和XLnet给出的参数集中做了一点超参数搜索;对于v2,,只是采用除RACE之外的V1参数,其中使用的学习率为1e-5和0 ALBERT DR。
Xxlarge
与初代ALBERT性能相比结果如下。
[TF-Hub]:
Large
Base
(原标题:谷歌ALBERT模型V2+中文版来了:之前刷新NLP各大基准,现在GitHub热榜第二)
而最近,谷歌开源了中文版本和Version 2,项目还登上了GitHub热榜第二。